


业界 | NIPS 2017前瞻:腾讯AI Lab八篇论文入选
2017年09月20日 15:17:40
来源:机器之心

原标题:业界 | NIPS 2017前瞻:腾讯AI Lab八篇论文入选 机器之心转载 腾讯AI La
原标题:业界 | NIPS 2017前瞻:腾讯AI Lab八篇论文入选
机器之心转载
腾讯AI Lab
本文将详解腾讯 AI Lab 入选 NIPS 2017 的八篇论文,及对机器学习未来研究方向的一点思考。
被誉为神经计算和机器学习领域两大顶级会议之一的 NIPS(另一个为 ICML)近日揭晓收录论文名单,机器之心梳理论文时发现国内有四家公司论文入选 NIPS 2017,四家公司分别为腾讯、百度、大疆、奇虎360。其中,腾讯 AI Lab 共有八篇论文入选,位居国内企业前列,其中一篇论文被选做口头报告(Oral)。这篇文章对腾讯 AI Lab 八篇入选论文做了简要介绍。
本届 NIPS 共收到 3240 篇论文投稿,创历年新高,其中 678 篇被选为大会论文,录用比例 20.9%。其中有 40 篇口头报告(Oral)和 112 篇亮点报告(Spotlight)。会议门票也在开售不到一小时内售罄,参会人数预计将超过去年的 5000 人,火爆程度可见一斑。

机 器 学 习 未 来 研 究 的 一 点 思 考
NIPS 的内容涵盖认知科学、心理学、计算机视觉、统计语言学和信息论等领域,可由此窥见机器学习最为前沿和备受关注的研究领域。而在思考未来方向时,我们认为研究者们可追本溯源,沉下心来关注一些本质问题。
比如机器学习研究方向之一,是探索如何在特定知识表达体系下有效利用不同资源,这里的资源包括计算资源(时间复杂性)和数据资源(样本复杂性)。这个方向上的主流思路是使用基于深度网络的模型,但近几年的研究更较偏 heuristic 和 empirical,而未来则更可能会是在深度模型的知识表达体系下进行探索。深度模型带来的最大挑战是非凸性,这从本质上有别于传统的计算与统计理论,也值得研究者们产生一些全新的思考。
深度学习是目前毋庸置疑的大趋势,近几年来此类研究空前火热,如果我们回到初心,将部分不真实的内容逐步澄清,能促进研究走上良性发展之路。
腾 讯 AI Lab 八 篇 入 选 论 文 详 解
*论文按标题英文首字母排序
Oral 论文 1. 去中心化算法能否比中心化算法效果更佳-一个关于去中心化的随机梯度方法研究
Can Decentralized Algorithms Outperform Centralized Algorithms? A Case Study for Decentralized Parallel Stochastic Gradient Descent
本论文与苏黎世联邦理工学院、加州大学戴维斯分校和 IBM 合作完成。并行优化和计算效率是从大数据发掘智能的核心竞争力。为了提高效率,大多数的并行优化算法和平台集中在研究中心化的算法,比如 Tensorflow、CNTK 及 MXNET。中心化的算法的主要瓶颈是上百个计算结点与(多个)中心节点之间的通讯代价和拥堵,严重的受制于网络的带宽和延迟。而这篇文章里则考虑去中心化的思路以减少通讯的代价。
尽管在去中心化的方法在控制领域已经有所应用和研究,但是考虑的是在特殊的去中心的拓扑结构的情况下,如何交换融合信息。而且已有的研究都没有表明如果二者都能用的情况下去中心的算法相对对于中心化的算法会有任何优势。这篇文章的主要贡献在于研究了一个去中心化的随机梯度方法,并且第一次从理论上证明了去中心化的算法可以比对应的中心化算法更加高效。同时本文通过大量的在深度学习上的实验和比较验证了作者理论。
这个发现将会打开未来大家对并行算法的思路,给并行系统带来更多的灵活性和自由度。我们相信将会对未来的机器学习平台和算法开发产生较大影响。
* 本文入选 NIPS 2017 口头报告(Oral),论文占比为 40/3248。
2. 线性动态系统上的高效优化及其在聚类和稀疏编码问题上的应用
Efficient Optimization for Linear Dynamical Systems with Applications to Clustering and Sparse Coding
本论文与清华大学和澳大利亚国立大学合作完成,其中的线性动态系统模型(LDS)是用于时空数据建模的一种重要的工具。尽管已有的理论方法非常丰富,但利用 LDS 进行时空数据的分析并不简单,这主要是因为 LDS 的参数并不是在欧氏空间,故传统的机器学习方法不能直接采用。
在这篇论文中,作者提出了一种高效的投影梯度下降法去极小化一个泛化的损失函数,并利用该方法同时解决了 LDS 空间上的聚类和稀疏编码问题。为此,作者首先给出 LDS 参数的一种新型的典范表示,然后巧妙地将目标函数梯度投影到 LDS 空间来实现梯度回传。与以往的方法相比,这篇文章中的方法不需要对 LDS 模型和优化过程加入任何的近似。充分的实验结果证明了这篇文章中的方法在收敛性和最终分类精度上优于目前最好同类方法。
3. 通过斯坦因引理估计高维非高斯多指数模型
Estimating High-dimensional Non-Gaussian Multiple Index Models via Stein』s Lemma
本论文与普林斯顿大学和乔治亚理工大学合作完成,作者探讨了在高维非高斯设置中估计半参数多指数模型的参数化组分的方法。文中的估计器使用了基于二阶斯坦因引理的分数函数,而且不需要文献中做出的高斯或椭圆对称性假设。内部机构的研究表明:即使分数函数或响应变量是重尾(heavy-tailed)分布的,文中的估计器也能实现接近最优的统计收敛率。最后,作者利用了一个数据驱动的截断参数,并基于该参数确定了所需的集中度(concentration)结果。作者通过模拟实验对该理论进行了验证,对这篇文章中的理论结果进行了补充。
4. 基于几何梯度下降方法的复合凸函数最小化
Geometric Descent Method for Convex Composite Minimization
本论文与香港中文大学和加利福尼亚大学戴维斯分校合作完成,主要扩展了 Bubeck, Lee 和 Singh 近期提出的处理非光滑复合强凸函数优化问题的几何梯度下降方法。文中提出「几何邻近梯度下降法」算法——能够以线性速率收敛,因此能相比其他一阶优化方法达到最优的收敛速率。最后,在带有弹性网络正则化的线性回归和逻辑回归上的数值实验结果表明,新提出的几何邻近梯度下降法优于 Nesterov's 加速的邻近梯度下降法,尤其面对病态问题时优势更大。
5. 基于混合秩矩阵近似的协同过滤
Mixture-Rank Matrix Approximation for Collaborative Filtering
本论文与复旦大学和 IBM 中国合作完成,关于低秩矩阵近似方法(LRMA)现今在协同过滤问题上取得了优异的精确度。在现有的低秩矩阵近似方法中,用户或物品特征矩阵的秩通常是固定的,即所有的用户或物品都用同样的秩来近似刻画。但本文研究表明,秩不相同的子矩阵能同时存在于同一个用户-物品评分矩阵中,这样用固定秩的矩阵近似方法无法完美地刻画评分矩阵的内部结构,因此会导致较差的推荐精确度。
这篇论文中提出了一种混合秩矩阵近似方法(MRMA),用不同低秩矩阵近似的混合模型来刻画用户-物品评分矩阵。同时,这篇文章还提出了一种利用迭代条件模式的领先算法用于处理 MRMA 中的非凸优化问题。最后,在 MovieLens 系统和 Netflix 数据集上的推荐实验表明,MRMA 能够在推荐精确度上超过六种代表性的基于 LRMA 的协同过滤方法。
6. 凸差近似牛顿算法在非凸稀疏学习中的二次收敛
On Quadratic Convergence of DC Proximal Newton Algorithm in Nonconvex Sparse Learning
为求解高维的非凸正则化稀疏学习问题,我们提出了一种凸差(difference of convex/DC)近似牛顿算法。我们提出的算法将近似牛顿算法与基于凸差规划的多阶段凸松弛法(multi-stage convex relaxation)结合到了一起,从而在实现了强计算能力的同时保证了统计性。具体来说,具体来说,通过利用稀疏建模结构/假设的复杂特征(即局部受限的强凸性和 Hessian 平滑度),我们证明在凸松弛的每个阶段内,我们提出的算法都能实现(局部)二次收敛,并最终能在仅少数几次凸松弛之后得到具有最优统计特性的稀疏近似局部最优解。我们也提供了支持我们的理论的数值实验。
7. 用于稀疏学习的同伦参数单纯形方法
Parametric Simplex Method for Sparse Learning
本论文与普林斯顿大学、乔治亚理工大学和腾讯 AI 实验室合作完成,作者关注了一种可形式化为线性规划问题的广义类别的稀疏学习——这类线性规划问题可以使用一个正则化因子进行参数化,且作者也通过参数单纯形方法(parametric simplex method/PSM)解决了这个问题。相对于其它相竞争的方法,这篇文章中的参数单纯形方法具有显著的优势:(1)PSM 可以自然地为正则化参数的所有值获取完整的解决路径;(2)PSM 提供了一种高精度的对偶证书停止(dual certificate stopping)标准;(3)PSM 只需非常少的迭代次数就能得到稀疏解,而且该解的稀疏性能显著降低每次迭代的计算成本。
特别需要指出,这篇文章展示了 PSM 相对于多种稀疏学习方法的优越性,其中包括用于稀疏线性回归的 Dantzig 选择器、用于稀疏稳健线性回归的 LAD-Lasso、用于稀疏精度矩阵估计的 CLIME、稀疏差分网络估计和稀疏线性规划判别(LPD)分析。然后作者提供了能保证 PSM 总是输出稀疏解的充分条件,使其计算性能可以得到显著的提升。作者也提供了严密充分的数值实验,演示证明了 PSM 方法的突出表现。
8. 预测未来的场景分割和物体运动
Predicting Scene Parsing and Motion Dynamics in the Future
本论文与新加坡国立大学、Adobe 研究室和 360 人工智能研究院合作完成。无人车和机器人这样的对智能系统中,预期未来对提前计划及决策非常重要。文中预测未来的场景分割和物体运动帮助智能系统更好地理解视觉环境,因为场景分割能提供像素级语义分割(即何种物体在何处会出现),物体运动信息能提供像素级运动状态(即物体未来会如何移动)。本文提出了一种全新的方法来预测未来的未观测到的视频场景分割和物体运动。用历史信息(过去的视频帧以及对应的场景分割结果)作为输入,文章中的新模型能够预测未来任意帧的场景分割和物体运动。
更重要的是,这篇文章中的模型优于其他分开预测分割和运动的方法,因为文中联合处理这两个预测问题以及充分利用了它们的互补关系。据内部统计,文中的方法是第一个学习同时预测未来场景分割和物体运动的方法。在大规模 Cityscape 数据集上的实验表明,本文的模型相比精心设计的基线方法,能获得显著更好的分割和运动预测结果。另外,这篇论文也展示了如何用机构内部的模型预测汽车转向角,获得的优秀结果进一步证实了该新模型学习隐含变量的能力。
一 分 钟 数 读 NIPS
NIPS 全称为 Annual Conference and Workshop on Neural Information Processing Systems,于 1986 年在由加州理工学院和贝尔实验室组织的 Snowbird 神经网络计算年度闭门论坛上首次提出。会议固定在每年 12 月举行。今年是第 31 届,将于 12 月 4 日到 9 日在美国西岸加州南部的长滩市(Long Beach)举办。
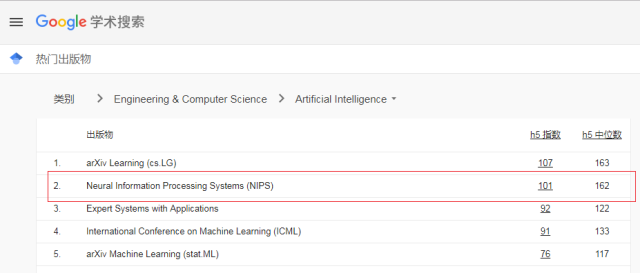
计算机学科由于成果更新迅速,更愿意通过会议优先发表成果,因此该类顶级会议大多比期刊更具权威性与影响力。NIPS 和 ICML 是机器学习领域最受认可的两大顶会,是中国计算机学会 CCF 推荐的 A 类会议及 Google 学术指标前五名。(见如下)

本文为机器之心转载,转载请联系原公众号获得授权。
✄------------------------------------------------


- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考













频道推荐

凤凰科技官方微信
视频
-

李咏珍贵私人照曝光:24岁结婚照甜蜜青涩
播放数:145391
-

金庸去世享年94岁,三版“小龙女”李若彤刘亦菲陈妍希悼念
播放数:3277
-

章泽天棒球写真旧照曝光 穿清华校服肤白貌美嫩出水
播放数:143449
-

老年痴呆男子走失10天 在离家1公里工地与工人同住
播放数:165128






